计算机网络
计算机网络体系结构
- OSI 体系结构:官方倡导理论标准。概念清楚、理念完整,但复杂、不实用。
- TCP / IP 结构:业界通用实际标准。是 Internet 的核心协议,简化了 OSI。
- 五层体系结构:融合了 OSI 与 TCP / IP 的体系结构,是学习计算机网络的基本结构。
第五章 传输层
传输层的主要知识点:UDP、TCP、停止等待协议、拥塞控制、可靠传输、滑动窗口、累计确认、端口。
UDP 主要特点
用户数据报协议 UDP(User Datagram Protocol),UDP 用户数据报。
UDP 其实只是在 IP 的数据报服务上,额外增加了端口的功能 + 差错检测的功能。
- 无连接。发送数据之前不需要建立连接,发送完数据也不需要释放连接,减少了开销和发送数据之前的握手时延。
- 尽最大努力交付。不保证可靠交付,主机不需要维持复杂的连接状态表,但数据的可靠性不能保证。通过向前纠错、重传已丢失报文等方式,尽可能确保可靠。
- 面向报文。UDP 一次交付一个完整的报文。其对应用层交下来的报文,既不合并,也不拆分,保留这些报文的边界,直接添加首部后就向下交付 IP 层。应用层给 UDP 多长的报文,UDP 一次就发送多长的报文。然而到了 IP 层后,可能根据长度要进行分段,所以过长的 UDP 报文段会影响 IP 层的传输效率。
- 没有拥塞控制。如果网络出现拥塞,也不会使源主机的发送速率降低。如 IP 电话、视频直播等等需要实时的应用,要求源主机以相对稳定的速率发送数据,且允许网络拥塞时丢失部分数据,但强调数据不能有过大时延。
- 支持一对多/多对一通信。
- 首部开销小。首部只有 8 字节,比 TCP 20 字节小得多。
有些应用程序愿意采用不可靠的 UDP,而不愿意采用可靠的 TCP。
- TCP 出现分组出错、丢失,会选择重传,增加了时延。
- TCP 出现拥塞时,拥塞控制另发送方放慢发射速度。
- UDP 出现分组出错会直接丢弃,出现拥塞也不会放慢速度。实时性强,适用于语音通话。
UDP 数据报的检验:
- 通过校验和检查:伪首部(IP 等关键信息)+ 首部 + 数据。
- 既检查了 UDP 相关信息:源端口号、目的端口号,也检查了 IP 相关信息:源 IP 地址、目的 IP 地址。
IP 数据报的检验:
- 检查:只检查首部。
TCP 主要特点
传输控制协议 TCP(Transmission Control Protocol),TCP 报文段。
-
面向连接。应用在使用 TCP 通信之前,必须建立 TCP 连接。传输数据完毕后,必须释放 TCP 连接。
-
可靠交付。通过 TCP 连接传输的数据,无差错、不丢失、不重复、按序到达。
-
面向字节流。流 stream 是指 TCP 的通信形式是面向字节流。虽然应用程序交付给 TCP 的是一个数据块(大小不等),但 TCP 根据 网络拥塞程度 + 对面接受窗口 切分为长度不一的字节流(TCP 报文段),添加首部后传输。
- 拥塞控制:根据网络拥塞程度,调整传输的字节长度。
- 流量控制:根据对方接受的窗口大小,调整传输的字节长度。确保发送方的发送速率不要太快,让接收方来得及接受。
-
点对点 + 全双工通信。
- 点对点:TCP 的通信双方只能是一对一的端口,不能一对多 / 多对一通信;
- 全双工:建立 TCP 连接后,通信双方可以在任何时候发送数据。TCP 连接的两端也有发送 / 接受缓存,临时存放双向通信的数据。
-
选择重传 + 滑动窗口,实现了 TCP 的可靠传输、流量控制。
TCP 流量控制
TCP 的流量控制:就是抑制发送方的发送速率,既要让接收方来得及接受,也不要使网络拥塞。
- 零窗口等待。TCP 为每一个连接设置 持续计时器,只要 TCP 连接的一方接收到对方的 零窗口通知,就启动 持续计时器,并停止发送。持续计时器到期后,发送一个 零窗口探测报文段(1B) 如果对方回复窗口仍然是零,重新启动持续计时器;若窗口不是零,死锁的僵局打破。
- 滑动窗口。发送方的发送窗口不能超过接收方给的接受窗口的数值。
- 传输效率提升:
- 最大长度。TCP 维护一个最大报文长度 MSS,只要缓存中存放的数据达到 MSS,就组成一个 TCP 报文段发送;
- push 发送。TCP 支持 push 操作,接收方可指定优先度高的报文,优先 push 发送;
- 到期发送。TCP 对缓存的数据添加计时器,如果到期后,即使数据量没达到 MSS,也立即发送。
TCP 拥塞控制
出现资源拥塞的条件是:对资源需求的总和 ≥ 可用资源。
与流量控制不同,拥塞控制是一个全局性的过程,涉及网络内的所有主机、路由器等在网设备,而流量控制仅针对点对点通信。如果不进行拥塞控制,随着负载的提升,全网络设备会进入死锁状态。
- 接收端窗口 rwnd、拥塞窗口 cwnd、往返时间 RTT。
- 发送窗口的上限 =
Min [rwnd, cwnd], [接收窗口, 拥塞窗口]。
![截屏2022-08-11 10.57.34[50]](/assets/images/截屏2022-08-11 10.57.34-fec22d1a39c4b48bb336b82e97c87b39.png)
- 慢开始:
- 在刚开始发送报文段时,可先将拥塞窗口 cwnd = 1,即一个最大报文段 MSS。
- 每收到 1 个报文段的确认,cwnd 加 1,即加一个 MSS 大小;
- 相当于:每经过一个传输轮次 RTT,cwnd 翻倍。如果收到 4 个确认,就 + 4。
- 窗口缓慢增加,试探网络的吞吐量。
- 拥塞避免:
- 设置一个慢开始门限 ssthresh;
- 当 cwnd < ssthresh 时,使用慢开始算法;
- 当 cwnd > ssthresh 时,停止慢开始,使用 拥塞避免算法;
- cwnd 每经过一个传输轮次 RTT,cwnd 加一个 MSS 大小,即 “加法增大”。
- 线性规律缓慢��增长,速率放缓。
- 乘法减小:
- 慢开始阶段、拥塞避免阶段。出现超时,网络拥塞(没有按时收到确认);
- ssthresh 减半,执行慢开始算法。
- 当网络频繁拥塞时,ssthresh 值下降得快,大大减少注入到网络中的分组数。
- 加法增大:
- 拥塞避免算法后,使拥塞窗口 cwnd 缓慢变大,每个 RTT 加 1。
- 防止网络过早出现拥塞。
- 拥塞避免算法后,使拥塞窗口 cwnd 缓慢变大,每个 RTT 加 1。
数据帧的丢失是网络发生拥塞的征兆,而不是原因:
- 快重传:接收方只要收到失序的报文段,立刻发出重复确认。
- 使发送方及早知道有报文段没有到达对方。
- 接收方立即发送,不进行捎带确认,不选择等待自已发送数据时发送。
- 快恢复:
- 发送方连续收到三个重复的确认。
- 执行 “乘法减小”,让慢开始门限 ssthresh 减半。
- 使 cwnd = ssthresh (已经减半),执行拥塞避免(加法增大),而不是重新慢开始。
TCP 可靠传输
可靠传输的基石,就是 停止等待 + 自动重传 + 滑动窗口。
停止等待:就是发送方没发送完一个分组,就停止发送,等待对方确认。收到确认后再发送下一个分组。停止等待协议要求通信数据包必须有双方协商好的编号。
滑动窗口:停止等待协议每次只允许发送一帧,然后就等待对方确认信息。滑动窗口允许发送方维护一个控制流量的发送窗口,允许一次发送多帧。同时,接收方也维护了一��个接受窗口。
- 发送窗口:每收到一个确认帧,就对窗口中已经发送的帧做标记,当靠前的帧已完成确认,窗口就向前滑动,可以发送其他数据帧。
- 接受窗口:每收到一个确认帧,就根据编号按需放在接受窗口的缓存中,同时发送确认帧,当靠前的帧已按序接受,则可以打包向上交付,同时移动接受窗口,接受后面序号的帧。若收到的数据帧在接受窗口之外,直接丢弃。
自动重传请求 ARQ Automatic Repeat ReQuest:就是 确认请求 + 超时重传。发送方的重传是通过超时而自动进行的,不需要接收方请求发送方重传某个出错的分组。
连续 ARQ 协议:发送方不需要收到当前帧确认后,才发送接下来的帧,而是批量发送多个帧,接收方也可以批量接受,然后批量发送确认帧,提升信道使用率。
停止-等待协议:发送窗口大小 = 1,接受窗口大小 = 1;
- 最简单版本,发送一个,确认一个,再发下一个。
后端 N 帧(GBN)协议:发送窗口大小 > 1,接受窗口大小 = 1;
- 累计确认:如果收到了 3 号帧确认,则 1、2、3 都可以确认。
- 捎带确认:接收方可以在发送数据的同时,捎带发送确认信息。
- 按序确认:如果接收方收到的帧不是按序的,只能丢弃该帧和其余后续的帧,重复发送已经接受的确认帧。
选择重传(SR)协议:发送窗口大小 > 1,接受窗口大小 > 1。
- 选择重传:改进了后推 N 帧的丢弃问题,可以选择性的重传出错的帧。接受方也通过一个接受窗口,可以不按序接受帧,然后按序整理好后向上交付。
TCP 的三次握手
TCP 的传输连接分为三个阶段:建立连接、数据传输、释放连接。
![image.png[40]](/assets/images/1625840781415-771ff11b-c7ac-4729-8dfd-130a24f5c381-fdddc3a3ae0b3de3137e42f78d9f4e88.png)
每一方的状态变迁都是:CLOSED / LISTEN ➡️ SYN-SENT ➡️ SYN-RCVD ➡️ ESTABLISHED
- 关闭且被动监听、发送自身同步码、确认对方同步码、建立连接。
第一次握手:
-
客户端主动打开,通过 TCP 向服务器发出连接 请求报文段,工作有二:
-
设置报文段首部的同步位 SYN = 1。不携带数据,消耗一个序号。
-
随机设置序号 seq = x,表明传送数据时的第一个数据字节的序号是 x。
-
第二次握手:
- 服务器监听到 TCP 数据报,通过同步位 SYN = 1 直到这是一个连接的请求,如果同意,回复 确认报文段,工作有三:
- 设置报文段首部的同步位 SYN = 1。不携带数据,消耗一个序号。
- 设置报文段首部的确认位 ACK = 1,序号为 seq = x + 1。
- 设置自己的序号 seq = y,表明传送数据时的第一个数据字节的序号是 y。
第三次握手:
- 客户端收到确认报文,通过确认位 ACK = 1 知晓服务器已经确认,发送 确认报文段 + 携带数据,工作有三:
- 客户端 TCP 通知上层应用进程,连接已经建立。
- 设置报文段首部的确认位 ACK = 1,序号为 seq = y + 1。
- 此时 TCP 已经建立,ACK 报文段可以携带数据(没有 SYN 字段),如果不携带数据、只确认则不消耗序号。
TCP 的四次挥手
一旦数据传输结束,客户端或服务器都可以主动请求释放连接。
![截屏2022-08-11 16.39.07[40]](/assets/images/截屏2022-08-11 16.39.07-2946f6af6a5ac3ef32a20735b798913c.png)
第一次挥手:
- A 进程主动通知 TCP 关闭连接,停止发送数据,开始被动监听数据,发送 连接释放报文段。
- 设置报文段首部的结束位 FIN = 1,假如此时序号为 seq = u。
- 不携带数据。
第二次挥手:
- B TCP 收到连接释放信号,通知上层进程,发送确认。此时 A 对 B 的 TCP 连接已经中断了。
- 正常确认收到:ack = u + 1,
- 正常发送序号:seq = v,可正常携带数据。
第三次挥手:
- 若 B 已经没有要发送的数据,其应用进程就通知 TCP 释放,发送 链接释放报文段。
- 设置报文段首部的结束位 FIN = 1,假如此时序号为 seq = v + n。
- 不携带数据。
第四次挥手:
- A 收到链接释放报文段后,必须发送确认收到。
- 确认收到:ack = v + n + 1,
- 发送序号:seq = u + 1。
- A 发送报文后,等待 2 MSL 后才真正释放连接。
三次 + 四次的原因
建立连接的两个任务:
- 确认对方身份,确保对方没有拒绝通信。
- 协商双方的初始序号,确保数据按序、不丢失的到达。
所以,和打电话一样,可以举一个打电话的例子。双方建立通信时,要发送一个 自身身份 + 自身序号的报文,也要接受一个对方确认的报文。而能完成这项工作的最少握手次数,就是 3 次。
不使用两次握手,也是为了防止 已失效的连接请求报文段突然又传送到了服务端,因而产生错误:
- 客户端首先向服务器发送了一个 SYN 报文,由于网络拥堵,迟迟没有收到响应,于是客户端发送了一个新的 SYN 报文。
- 但是旧的 SYN 报文比新的 SYN 报文要到达了服务器,此时服务器就返回 SYN+ACK 的报文给客户端。
- 因为只有 2 次握手,此时服务器以为连接已经建立,开始传输数据,但其实此时双方的初始序号没有协商成功,客户端并不知道初始序号是什么。
释放连接的两个任务:
- 双方发送释放连接请求,并确认对方收到释放请求。
- 先释放请求的一方,要保持监听,接收对方剩余的数据。
如果双方 “恰好” 同时结束通信,那么有可能 3 次挥手就释放连接:
- A 主动释放连接,发送 FIN = 1,并不再发送数据;
- B 收到释放请求,此时也 “恰好” 好释放连接,发送 确认 + FIN = 1,B 结束 TCP 连接。
- A 收到释放请求,发送释放确认,并在 2MSL 后结束 TCP 连接。
这就解释了为什么大多数情况下要 4 次挥手。因为被动结束的一方,有可能在结束前还要发送数据,所以发送和接收端都要发送 FIN + ACK FIN 这两个报文,一共就是四次。
问:为什么挥手最后要等待 2MSL?
MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任�何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
A 为了保证最后一个 ACK 报文段对方 B 能顺利接收。假设此时这个 ACK 报文段在网络中丢失。B 在 2MSL 中会再次发送一个 FIN 释放请求连接,继续等待 A 的 ACK 报文段,此时 A 依然在自身的 2MSL 中监听,当它又收到一个 FIN 请求后,知晓上一个 ACK 可能已经丢失,立即重发,并继续等待 2MSL。这样就确保双方都能确认释放,进入 CLOSED 状态。
- 特例:如果第一个 ACK 报文丢失,且后面重发的 FIN 报文段也丢失,A 误认为连接结束,主动 CLOSED。而 B 还孜孜不倦的发送 FIN 报文段。在多次没有回应后,也会 CLOSED。
TCP 的重传机制
首先,在正常情况下,当发送端的数据到达接收主机时,接收端主机会返回一个已收到消息的通知,叫做确认应答(ACK)。TCP 通过序列号 seq 和 ACK 实现可靠传输。如果数据包丢失,会用重传机制解决。
超时重传
自动重传请求 ARQ:(上文)
在发送数据时设定定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据。TCP 会在数据包丢失或者确认应答丢失的情况下发生超时重传。
超时时间的设置:
RTT (Round-Trip Time 往返时延)。数据从网络一端传送到另一端所需的时间 x 2。
**RTO 超时重传时间 **。是一个基于算法的动态变化值,RTO 略大于报文往返 RTT。
- 当 RTO 较大时,重发慢,效率低;
- 当 RTO 较小时,重发快,可能��并没有丢就重发,增加网络拥塞,导致更多的超时。
快速重传
3 次确认快重传。
当某个报文段丢失后,发送端会一直收到某个序号的确认应答,如果发送端连续三次收到了同一个确认应答报文,就会将其所对应的数据进行重发。
为什么是 3 次?因为有可能报文并没有丢失,只是因路由选择的原因时延过长。
第六章 应用层
http 常见字段
-
Host 字段:客户端 发送请求时,用来指定服务器的域名。
-
Content-Length 字段:服务器 在返回数据时表明本次回应的数据长度。
-
Connection 字段 :客户端 要求服务器使用 TCP 持久连接,以便其他数据发送复用。HTTP/1.1 版本的默认连接都是持久连接,但为了兼容老版本的 HTTP,需要指定 Connection 首部字段的值为 Keep-Alive 。
-
Content-Type 字段 :服务器 告知客户端本次数据是什么格式;客户端 请求时声明自己可以接受哪些数据格式。
-
Content-Encoding 字段:服务器 返回的数据使用的压缩格式。 客户端 在请求时声明可以接受的压缩格式。
HTTP 常用的请求方式 (9)
HTTP1.0: GET、POST、HEAD
HTTP1.1: PUT、PATCH、DELETE、OPTIONS、TRACE、CONNECT
- GET:通用获取数据
- POST:提交数据
- DELETE:删除数据
- TRACE:追踪请求-响应的传输路径,用于测试或诊断
- HEAD:获得报文首部
- PUT:修改数据
- PATCH:对 PUT 的补充,对已知资源部分更新
- CONNECT:建立连接隧道,用于代理服务器
- OPTIONS:列出可对资源实行的请求方法,常用于跨域
Options 请求的作用
用于客户端请求服务器,支持哪些通信协议(方法、头部、跨域权限等),不会传输实际数据。
-
CORS 预检请求(最常见):执行 **跨域请求(如 PUT/DELETE 或自定义 Header)**时,浏览器会先自动发送一个 OPTIONS 请求,称为预检请求(Preflight) ,目的是确认服务器是否允许此跨域操作。如果服务器允许,浏览器才会继续发送真正的 PUT 请求
-
查询资源支持的方法:可以用 OPTIONS 请求某个 URL,询问服务器支持哪些 HTTP 方法:
Allow: GET, POST, OPTIONS。
GET 和 POST 的区别
相同:
- 两者都是应用层中 HTTP 协议中的两种发送请求的方式,都通过 TCP 连接的可靠传输。
- 因 GET 和 POST 并不是强制约定的规则,而是一种倡导式的语义规范,只要前后端协商好,GET 也能当 POST 使用,body 上携带数据发送,只是这种方式是不建议的。
不同:
- 含义不同。
- GET 是请求从服务器获取资源,这个资源可以是静态的文本、页面、图片视频等。
- POST 是向服务器提交数据,数据通常放在 body 中。
- **安全不同。**所谓安全不同,是针对服务器而言的。安全 指请求方法不会破坏服务器上的资源。幂等,意思是多次执行相同的操作,结果都是相同的。
- GET 是安全且幂等的,它是 只读 操作,无论做多少次请求,服务器的数据不变。
- POST 是不安全、不幂等的。不安全:POST 会向服务器新增 / 修改数据,造成服务器资源的改变;不幂等:多次提交相同的数据,服务器也可能会保存多记录。
- 额外数据。POST 可以把数据放在请求体 (request body) 中传输数据。GET 只能通过 URL 传输。这导致:URL 的长度存在限制,数据总量受限;传输参数暴露在 URL 中,用户可以感知到。
- 数据包数量不同。这是浏览器的通常方式:
- GET:浏览器会把 请求行 + 头 + 体 一并发送出去,服务器响应 200(返回数据)
- POST:类似 三次握手,浏览器先发送 请求行 + 头,服务器响应 100 continue,再发送 请求体,服务器响应 200 ok(返回数据),确保服务器做好接受数据的准备。
HTTP 的特点 / 缺点
HTTP 是超文本传输协议,也就是 HyperText Transfer Protocol。HTTP 是一个传输层基于 TCP 连接,在应用层专门在 两点之间传输 文字、图片、音频、视频等 超文本数据 的 约定和规范。
特点:无连接、无状态、灵活、简单快速
- 无连接:每一次请求都要连接一次,请求结束就会断掉,不会保持连接。
- 无状态:每一次请求都是独立的,请求结束不会记录连接的任何信息 (提起裤子就不认人的意思),减少了网络开销,这 是优点也是缺点。减轻服务器的负担,不用记录所有客户端的信息。
- 可以通过携带 cookie 来控制客户端的状态,比如 sso 登陆。
- 灵活:通过 http 协议中头部的
Content-Type标记,可以传输任意数据类型的数据对象(文本、图片、视频等等),非常灵活。 - 简单快速:发送请求访问某个资源时,只需传送请求方法和 URL 就可以了,使用简单,正由于 http 协议简单,使得 http 服务器的程序规模小,因而通信速度很快。
缺点:无状态、不安全、明文传输、队头阻塞
- 无状态:请求不会记录任何连接信息,没有记忆,就无法区分多个请求发起者身份是不是同一个客户端的。如果后续处理需要前面的信息,则必须重传。这样可能导致每次连接传送的数据量增大。
- 不安全:
- 明文传输 可能被窃听:账号信息泄露。
- 缺少身份认证 可能遭遇伪装:访问到假的银行网站。
- 缺少 报文完整性验证 可能遭到篡改:网页注入垃圾广告。
- 队头阻塞:开启 长连接 时,只建立一个 TCP 连接,同一时刻只能处理一个请求,那么当请求耗时过长时,其他请求就只能阻塞状态。
HTTP 报文组成部分
http 报文:由请求报文和响应报文组成
请求报文:由请求行、请求头、空行、请求体四部分组成
响应报文:由响应行、响应头、空行、响应体四部分组成
- 请求行 :包含 http 方法,请求地址,http 协议以及版本
- 请求头/响应头:通过 key / value 告诉服务端我要哪些内容,要注意什么类型等。
- 空行:用来区分首部与实体,因为请求头都是 key / value 格式,当解析遇到空行时,服务端就知道下一个不再是请求头部分,就该当作请求体来解析。
- 请求体:请求的参数
- 响应行:(状态行)包含 http 协议及版本、数字状态码、状态码英文名称
- 响应体:服务端返回的数据
HTTP1.1 持久连接/长连接
HTTP 1.0 协议:采用的是 "请求-应答" 模式。每发起一个请求,都要新建一次 TCP 连接(三次握手),而且是串行请求,做了无谓的 TCP 连接建立和断开,增加了通信开销。http 协议为 无连接 的协议。
HTTP 1.1 协议:支持长连接,即请求头添加 Connection: Keep-Alive,使用 Keep-Alive 模式 (又称持久连接) 建立一个 TCP 连接后使客户端到服务端的连接持续有效,可以发送/接受多个 http 请求/响应。当出现对服务器的后续请求时,Keep-Alive 功能避免了建立或者重新建立连接。
优点
- 减少 CPU 及内存的使用,因为不需要经常建立和关闭连接
- 支持管道化 的请求及响应模式
- 减少网络堵塞,因为减少了 TCP 请求
- 减少了后续请求的响应时间,因为不需要等待建立 TCP、握手、挥手、关闭 TCP 的过程
- 发生错误时,也 可在不关闭连接的情况下进行错误提示
缺点
- 长连接建立后,如果一直保持连接,服务器资源浪费,影响到 并发数。
- 可能造成 队头堵塞,造成信息延迟
避免缺点
- 客户端即时断开。客户端请求头声明:
Connection: close,本次通信后就关闭连接; - 服务端超时断开。如 Nginx,设置
keepalive_timeout长连接超时时间。 - 服务端限制并发。如 Nginx,设置
keepalive_requests长连接请求次数上限。 - 设置保活计时器。如果 TCP 闲置 60s 后,客户端可主动发送侦测包,确定 TCP 的连接状态。如果没收到 ACK 确认,就 10s 后继续发送。连续 5 次失败,则关闭 TCP 连接。
HTTP1.1 管道化/管线化
http1.1 在使用长连接的情况下,建立一个连接通道后,连接上消息的传递类似于
- 请求 1 -> 响应 1 -> 请求 2 -> 响应 2 -> 请求 3 -> 响应 3
管道化 连接的消息就变成了类似这样
- 请求 1 -> 请求 2 -> 请求 3 -> 响应 1 -> 响应 2 -> 响应 3
管线化 :类似 TCP 连接的滑动窗口机制。基于长连接下,发一个请求后不必等待确认,就继续发其他请求。
- 优点:可以减少整体的响应时间。
- 缺点:队头阻塞。服务器还是 会按照请求的顺序响应 请求,所以如果有许多请求,而前面的请求响应很慢,就会产生队头阻塞。
HTTP 断点续传
HTTP/1.1 开始支持。
涉及 HTTP 头中的 Range 、 Content-Range 、If-Range。
**(1)**客户端发起请求,在 请求头 中 Range 字段 可以指定请求文件的开始-结束位置。
**(2)**服务端响应请求时,通过 响应头 中返回 Content-Range 字段表示当前发送数据的范围�和文件总大小。
- HTTP/1.1 200 Ok(不使用断点续传方式)
- HTTP/1.1 206 Partial Content(使用断点续传方式)
当文件发生传输终端后,重新开始请求资源片段时,必须确保上一个片段在接受之后,该资源没有进行过修改。
**(3)**客户端 请求头 携带 If-Range 字段,其值为 Etag HTTP/1.1 资源唯一标识 或 Last-Modified HTTP/1:资源最后修改时间。
- 如果服务器验证资源没有修改,则返回状态码 206 Partial Content ,通常在响应体中继续 发送剩余资源。
- 如果服务器验证资源修改,则返回状态码为 200 OK ,同时返回整个资源。
Etag、Last-Modified 是强缓存、协商缓存相关知识。
// 请求下载整个文件:
GET /test.rar HTTP/1.1
Connection: close
Host: 116.1.219.219
Range: bytes=0-499 // 如果请求下载整个文件。用 bytes=0- 或不用该字段
// 响应,断点续传:
HTTP/1.1 206 Partial Content
Content-Length: 200
Content-Type: application/octet-stream
Content-Range: bytes 0-199/1234 //1234:文件总大小
Https
HTTPS 是 超文本传输安全协议,即 HTTP + SSL/TLS。说白了,就是一个加强版的 HTTP。
- TLS 是 SSL 的升级版,目前主要用的是
TLS 1.2和TLS 1.3,分别是 2008 和 2018。 - OpenSSL 是 开源版本,从 2010 年开始维护。、
TLS 保证了计算机网络安全的五个特性:机密性、可用性、完整性、认证性、不可否认性。
![img[30]](/assets/images/9e99f797de30a15a11b0e4b4c8f810cf-8cf58d2b9ee983a98482dd94e62b067e.png)
安全层有两个主要的职责:对发起 HTTP 请求的数据进行加密操作和对接收到 HTTP 的内容进行解密操作。
HTTPS 融合了 对称加密 + 非对称加密 + 数字证书。达到性能与安全最大化。这套整合的技术我们称之为 SSL(Secure Scoket Layer 安全套接层)。所以 https 并非是一项新的协议,它只是在 http 上披了一层加密的外壳。
HTTP 和 HTTPS 的区别
- 安全性。HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。 HTTPS 在 TCP 和 HTTP 应用层之间加入了 SSL/TLS 安全协议,使报文能够加密传输。
- 额外握手。HTTP 在 TCP 三次握手之后便可进行 HTTP 的报文传输。
HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- TLS 是 传输层协议。
- 握手次数:TLS 1.2 版本 7 次,TLS 1.3 版本 6 次。
- 不同端口。HTTP 的端口号是 80,HTTPS 的端口��号是 443。
- 额外证书。如果使用 HTTPS 协议,服务器需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的,而额外的认证证书是需要收费的。
- 额外状态。HTTP 是 无状态 的,HTTPS 是 有状态 的。
- 每个 HTTP 请求都是独立的,服务器不会主动记住客户端的状态;
- 基于 TLS,通信前需建立一套状态(密钥、算法等),通信中双方共享加密状态。
HTTPS 优缺点
优点:
- 内容加密,中间无法查看原始内容。
- 身份认证,保证用户访问正确。如访问百度,即使 DNS 被劫持到第三方站点,也会提醒用户没有访问百度服务,可能被劫持。
- 数据完整性,防止内容被第三方冒充或篡改。
虽然不是绝对安全,但是现行架构下最安全的解决文案了,大大增加了中间人的攻击成本。
缺点:
- 收费,功能越强大的证书费用越贵。
- 证书需要绑定 IP,不能在同一个 IP 上绑定多个域名。
- https 双方加密 / 解密,耗费更多服务器资源。
- https 握手更耗时,降低一定用户访问速度。
HTTPS 加密算法
https 使用混合加密的形式,对称加密和非对称加密都会用到。通过 3 点实现数据加密安全:
- 非对称加密算法。公钥和私钥,交换对称加密中使用的密钥。
- 数字证书。数字证书验证身份,验证公钥是否是伪造。
- 对称密钥。利用对称密钥加解密后续传输的数据。
🔒 对称加密算法
加密和解密使用同一个密钥。如 AES、DES。加解密过程:
- 浏览器给服务器发送一个随机数
client-random和一个支持的加密方法可选列表。 - 服务器给浏览器返回另一个随机数
server-random和双方都支持的加密方法。 - 两者用加密方法将两个随机数混合生成密钥,这就是通信是加解密的密钥。
缺点问题:双方如何安全的传递两个随机数和加密方法。若直接传递,过程中可能被中间人窃取,便可解密拿到数据内容。
![img[50]](/assets/images/d86648267d5504c7813b2d692620503b-d1df5b632b708a438bf152ab790d7e2f.png)
🔒 非对称加密算法
有一对密钥,有 公钥 (public key)和 私钥 (private key),其中一个密钥加密后的数据,只能让另一个密钥进行解密。如 RSA、ECDHE。加解密过程:
- 浏览器给服务器发送一个随机数
client-random和一个支持的加密方法可选列表; - 服务器把另一�个随机数
server-random、加密方法、服务器公钥 传给浏览器。 - 然后浏览器用公钥将两个随机数加密,生成密钥,这个密钥只能用 服务器的私钥 解密。
问题:使用公钥反推出私钥的代价非常高,可能是几百年。但不是做不到,随着计算机运算能力提高,非对称密钥至少要 2048 位才能保证安全性,这就导致性能上要比对称加密要差很多。
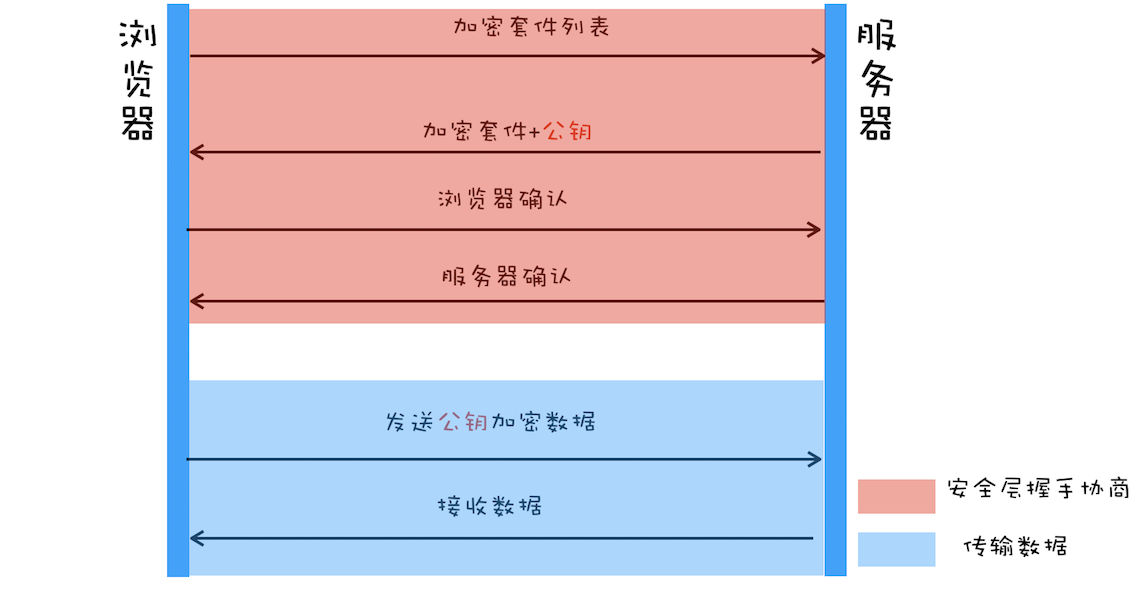
🔒 混合加密
TLS 实际用的是两种算法的混合加密。
- 非对称加密数据安全,但性能差。所以利用非对称加密先进行随机数 + 对称加密算法的传递。
- 然后通过对称加密数据传输,保证了会话的机密性。过程如下:
-
服务器非对称加密:双方获取 随机数 + 对称加密算法;
-
浏览器:给服务器发送一个随机数
client-random和一个支持的加密方法列表。 -
服务器:把第二个随机数
server-random、加密方法、服务器公钥 传给浏览器。 -
浏览器:又生成第三个随机数
pre-master,并用 服务器公钥 加密后传给服务器。 -
服务器:用私钥解密,此时已经拥有 3 个随机数
pre-random。
-
-
浏览器和服务器都将三个随机数用对称加密方法,混合生成最终密钥。
- 特点:这样即便被截持,中间人没有 服务器私钥 ,拿不到第三个
pre-random,无法生成最终密钥。
❗️ 问题:如果一开始就被 DNS 截持,我们拿到的公钥是中间人的,而不是服务器的,数据还是会被窃取。
- 解决:使用 数字证书。
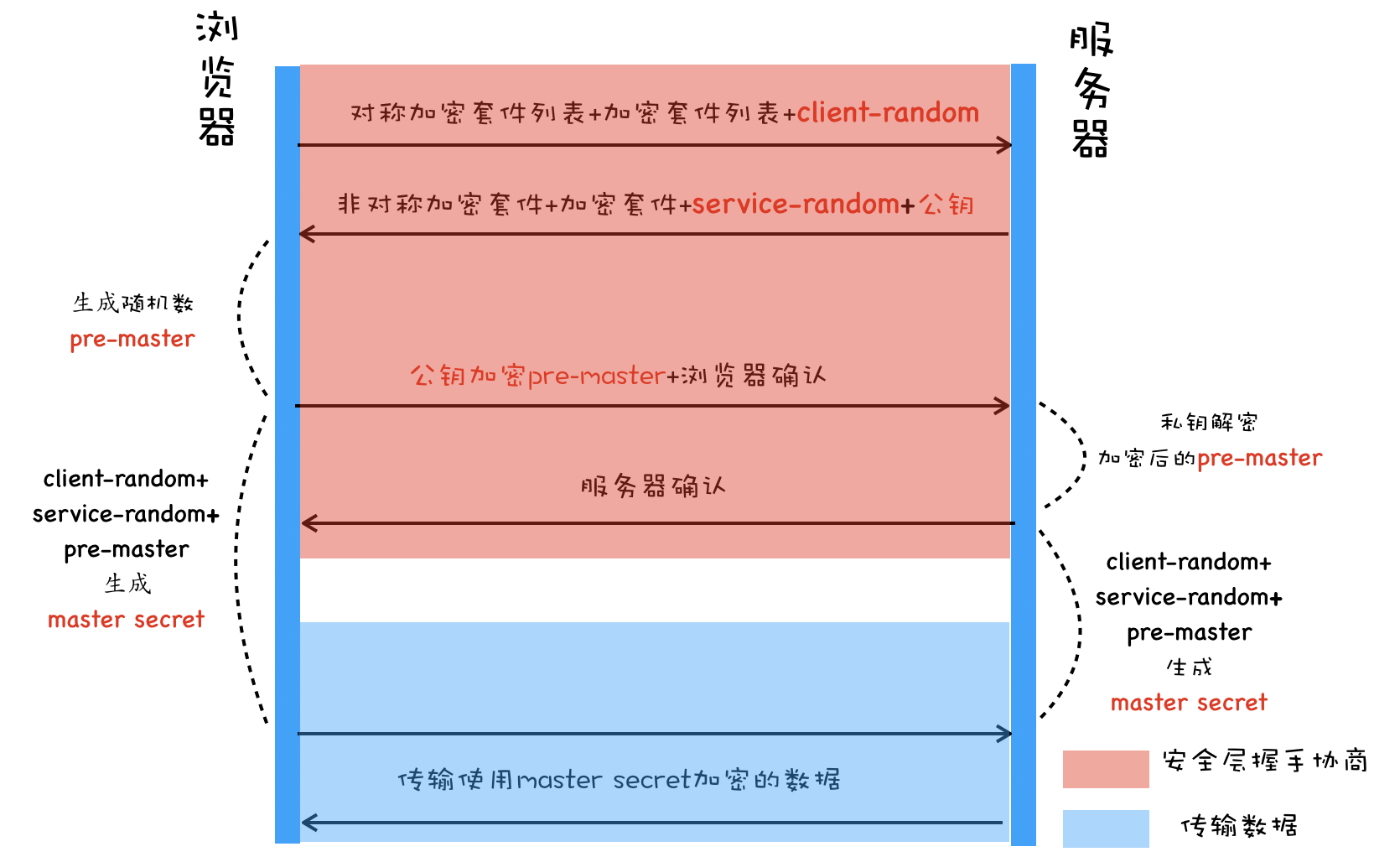
🔒 数字证书 (签名)
客户端用来 验证服务器身份,防止中间人攻击。既然客户端不信任服务器身份,那么就找一个信任的中间服务器( CA 机构),通过它的认证来信任服务器。
- 中间人劫持:假如请求被中间人截获,中间人把他自己的公钥给了客户端,客户端收到公钥就把信息发给中间人了,中间人解密拿到数据后,再请求实际服务器,拿到服务器公钥,再把信息发给服务器。这样信息就被窃取了。
数字证书需要向有权威的 认证机构(CA) 获取授权给服务器。
证书生成步骤:申请数字证书、CA 机构
- 服务器和 CA 机构分别有一对密钥 (公钥和私钥)。
- 服务器向 CA 机构递交公钥、公司、站点等信息并等待认证;
- CA 机构通过线上、线下等渠道验证服务器的真实性、合法性等,然后准备生成证书。
- CA 机构通过摘要算法生成 服务器公钥 的 摘要 (哈希摘要)。
- 摘要算法:保证信息完整性,特点是单向性、无法反推原文,如:MD5 算法、散列函数、哈希函数。
- CA 机构通过 CA 私钥 及特定的签名算法 加密 摘要,生成 签名。
- 把 签名、服务器公钥、组织信息、CA 信息、有效时间、证书序列号等 明文信息,打包放入 数字证书,并返回给服务器。
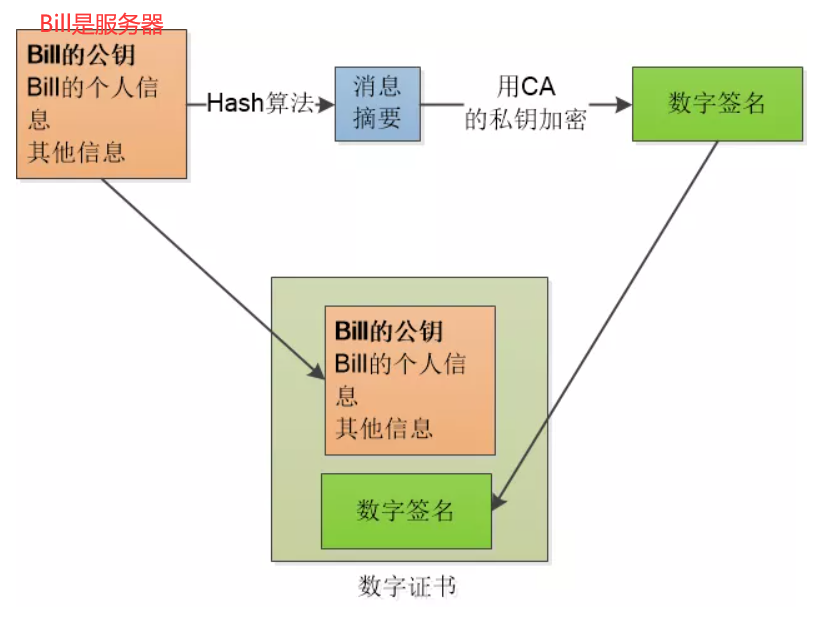
证书验证步骤:
-
证书中内容有:域名、CA 公钥、颁发者(CA 机构)、有效期、签名(CA 使用私钥对证书的摘要加密得到)。
-
验证证书链:浏览器读取证书中的颁发者,在本地受信任根证书列表中,查找该 CA。如果找不到,继续请求中间证书,知道找到根证书。
-
验证签名是否合法,对每一级证书都要验证签名:
-
原始摘要:使用 上一级 CA 机构的公钥 解密当前证书的数字签名;
-
hash 摘要:使用 摘要算法, 将证书里的内容,重新生成 hash 摘要。
-
最后把两个摘要进行比对,如果一致说明证书合法,服务器公钥正确,否则就是非法。
-
这里的核心,是 CA 的公钥必须可信,所以浏览器可能还要对 CA 进行验证,则要找到 CA 的数字签名,从更大的 CA 机构验证这个 CA 机构... 最后内置 CA 对应的证书称为根证书,根证书是最权威的机构,它们自己为自己签名,称为自签名证书。
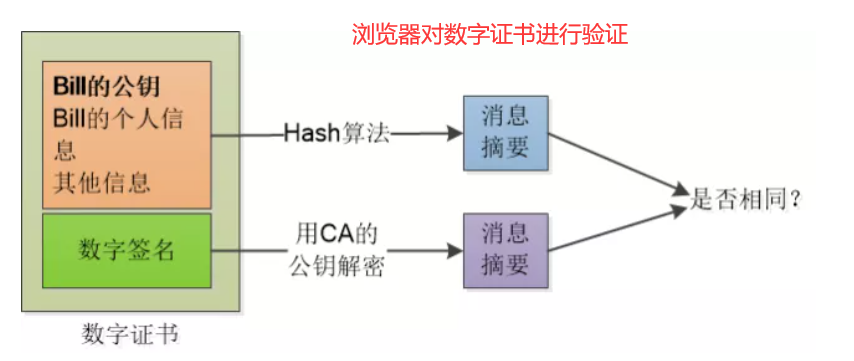
HTTPS 执行流程
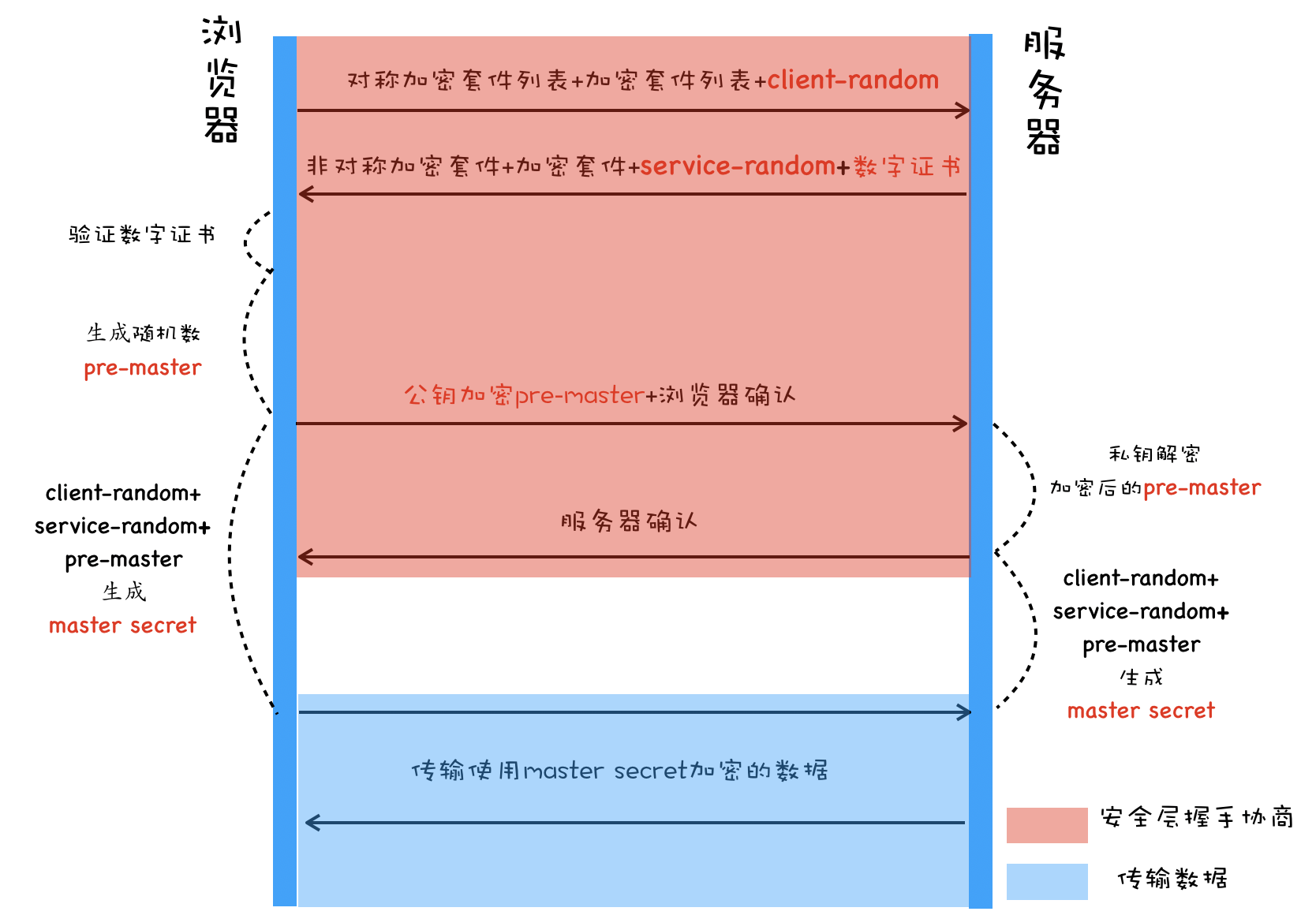
简述:
- 客户端请求:对称密钥 + 第一个随机数;
- 服务器响应:非对称加密服务器公钥 + 服务器数字证书 + 第二个随机数;
- 客户端验证证书:向上查找,获取可信 CA 机构的公钥,去验证数字证书;
- 客户端加密传输:验证通过后,将对称加密方法 + 第三个随机数,用服务器的公钥加密发送;
- 服务器组合密钥:服务器用私钥解密。在得到三个随机数 + 密钥生成方法后,构建生成最终的对称公钥。
双方都有三个随机数 + 对称密钥协议,都可以生成对称公钥,可以开始加密传输了(公钥没有在通信中传输过)。
队头阻塞
队头阻塞 Head-of-line blocking,HOL blocking。
- 存在于 HTTP 层、TCP 层,在 HTTP1.x 时两个层次都存在该问题。
TCP 层:TCP 协议在收到数据包之后,这部分数据可能是乱序到达的,数据必须按序整合后向上交付。如果其中某个包丢失了,就必须等待重传,从而出现某个丢包数据阻塞整个连接的数据使用。
- TCP 层,可以通过优先级调�整、滑动窗口增大等方式来缓解。
**HTTP 层:**同理,如果是乱序到达,依然存在阻塞的问题。
解决:HTTP/1.1 两个层都存在问题、HTTP/2 解决了 HTTP 层的阻塞问题、HTTP/3 解决了 TCP 层的阻塞问题;
-
HTTP/1.1:默认使用串行请求(每个 TCP 连接一次只能处理一个请求),基于 请求-应答 模式,多个请求必须排队执行,且没有优先级概念。这导致如果队首的请求耗时过长,后面请求只能处于阻塞状态。
- 解决方案 并发连接。 开启多个 TCP 连接,并发的发送请求;
- 解决方案 域名分片。同一个域名最多 6 个并发,那多准备 二级域名。比如 a.baidu.com,b.baidu.com,当访问 baidu.com 时,让不同的资源从不同的分域名获取,而它们都指向同一台服务器,并发更多的长连接了。
-
HTTP/2: 引入多路复用。把 HTTP 报文拆分为帧的形式,通过 stream ID,标识属于哪个请求流。所以服务端可以无序的发送帧,客户端根据 ID 重新组装成数据流,最后组装成完整响应。请求和响应不再是一问一答的顺序执行,而是帧级别的并发。
-
HTTP/3:直接不跟 TCP 玩了,使用 UDP。不存在严格按序的情况,丢包只影响当前流不影响其他流。
HTTP 演变: 1.1, 2, 3
(1)HTTP/1.1
-
持久�连接 + 管线化
-
HTTP/1.1 中增加了持久连接的方法,它的特点是在一个 TCP 连接上可以传输多个 HTTP 请求,只要浏览器或者服务器没有明确断开连接,那么该 TCP 连接会一直保持。
-
使用 CDN 的实现域名分片机制。将一个页面的资源利用多个域名下载,提高 tcp 并发数量。
-
-
支持动态生成
-
HTTP/1.0 时,需要在响应头中设置完整的数据大小,如 Content-Length: 901。
-
基于模板引擎技术的 HTML 网页大小变得不确定。浏览器不知道最终返回的数据量大小, 导致了浏览器无法数据是否传输完成。
-
HTTP/1.1 推出 chunk transfer 机制,从后端解决了这个问题。 服务端将数据分割成多个大小不一的数据块,并附上大小信息。最后使用一个没有 0 长度的块,专门作为发送数据完成的标志。
-
-
客户端 Cookie
-
HTTP/1.1 还引入了客户端 Cookie 机制,可以保持登录状态。
-
客户端输入用户名 + 密码,服务器验证通过后,会注入 Cookie 字段:
Set-Cookie: UID=3431uad;写到相应头中。 -
客户端再次访问服务器,会把 Cookie 字段写到请求头,服务器验证 Cookie 有效(正确 + 未过期)可让客户端保持登录状态。
-
缺点:对带宽的利用率不高,主要集中在 3 个问题:
-
TCP 的慢启动:TCP 建立连接后,为了拥塞控制,按照规定需要采用 慢启动/慢开始 策略。在刚开始发送报文段时,将拥塞窗口 cwnd = 1,即一个最大报文段 MSS。然后每个传输轮次 RTT 翻倍。
-
多条 TCP 连接竞争带宽:如果客户端对同一个服务器请求,同时开启了多条 TCP 连接,那么这些连接会竞争固定的带宽。每条 TCP 连接之间也并不知道对方在传输什么文件,哪些重要,哪些不重要。所以任务没有个轻重缓急。
-
队头阻塞:HTTP/1.1 使用持久连接时,多个请求任务公用一个 TCP 管道,存在队头阻塞的问题。当头的请求没有确认时,队列中其他的任务要白白等待。有些关键的任务因为要按序而没有提前发送。
(2)HTTP/2
HTTP/2 在 2018 年就开始得到了大规模的应用,HTTP/1 的一大堆缺陷都得到了解决。
多路复用。把 HTTP 拆分为帧的形式,形成数据流:
-
本质是将串行的请求处理并行化,为了实现功能需要双方多维护一个数据结构 — 帧。
-
解决问题 1 和 2:HTTP/2 使用 一个域名只使用一个 TCP 长连接来传输数据。这样整个页面资源的下载过程只需要一次慢启动,同时也避免了多个 TCP 连接竞争带宽所带来的问题。
-
解决问题 3:HTTP/2 实现资源的 并行请求(不按序)。任何时候都可以将请求发送给服务器,不需要按序,等其他请求完成。服务器也可以随时返回处理好的请求资源给浏览器,可以根据优先级有选择的不按序响应。
多路复用 延伸特性:
-
多路复用:HTTP2 建立一个 TCP 连接,一个连接上面可以有任意多个流(stream),消息分割成一个或多个帧在流里面传输。帧传输过去以后,再进行重组,形成一个完整的请求或响应。这使得所有的请求或响应都无法阻塞。
-
数据优先级。浏览器在发送请求时可标记优先级,期待服务器优先返回。服务器可根�据自身需求,选择哪些请求优先返回。
-
服务器推送。服务器可直接将数据提前推送到浏览器。当用户请求一个 HTML 页面之后,服务器知道该页面会引用了重要的 JavaScript 和 CSS 文件,所以会附带将文件一并发送给浏览器。这样当浏览器解析完 HTML 文件之后,就能直接开始解析 CSS、执行 Js。加速了首次打开页面的速度。
-
头部压缩。HTTP/2 对请求头和响应头进行了压缩。
HTTP/3
不论是 HTTP/1.1 还是 HTTP/2,都是基于 TCP 的 HTTP 协议。这就不可避免的带上了 TCP 的缺点:
- 队头阻塞。TCP 数据帧必须是按需到达,按序整理和向上交付的。滑动窗口、TCP 并发并不能从根本上解决问题。
- 建立连接。在正式通信前,可能要 3-4 个 RTT 传输轮次 (Round-Trip Time 往返时延)
- TCP 基于可靠传输,采用了三次握手的建立连接方式。需要 1.5 个 RTT。
- 为了确保通信安全,HTTPS 增加 TLS / SSL 的握手时间。需要约 2 个 RTT。
- 慢启动。TCP 为了拥塞控制,要从 1 慢开始。
由于 TCP 无法改变:
- 中间设备的固化,多数中间设备是不进行固件更新的:路由器、防火墙、交换机。
- TCP 协议的加载和解析方式是基于操作系统内核的。
引入新的 QUIC 协议。基于 UDP,集成 **TCP + HTTP/2 多路复用 + HTTPS TLS ** 的一套协议。
- 实现 TCP 的 流量控制、可靠传 功能。QUIC 提供数据包重传、拥塞控制等 TCP 特性,解决 UDP 不可靠的传输。
- 集成了 TLS 加密功�能。目前 QUIC 集成 TLS1.3,比早期版本减少握手花费的 RTT 个数。
- 实现 HTTP/2 的 多路复用功能。和 TCP 不同,QUIC 实现了在同一物理连接上可以有多个独立的逻辑数据流。实现了数据流的单独传输,就解决了 TCP 中队头阻塞的问题。
- 快速握手。QUIC 是基于 UDP,实现使用 0-RTT 或者 1-RTT 来建立连接。用最快的速度来发送和接收数据,大大提升首次打开页面的速度。
网络安全
常见网络攻击方式
被动攻击:是指攻击者从网络上窃听他人的通信内容,通常把这类攻击称为截获。由于攻击者没有修改数据,使得这种攻击很难被检测到。
- 两种形式:消息内容泄露攻击 和 流量分析攻击。
主动攻击:直接对现有的数据和服务造成影响,常见类型有:
- 篡改:攻击者故意篡改网络上送的报文,甚至把完全伪造的报文传送给接收方。
- 恶意程序:恶意程序种类繁多,包括计算机病毒、计算机蠕虫、特洛伊木马、后门入侵、流氓软件等等。
- 拒绝服务 Dos:攻击者向服务器不停地发送分组,使服务器无法提供正常服务。
DNS 劫持:域名劫持
- 将原域名对应的 IP 地址进行替换,使用户访问到错误网站。
CSRF 攻击:跨站请求伪造 Cross-site request forgery。
- 一种挟持用户在当前已登录的 Web 应用程序上执行非本意的操作的攻击方法。
DOS:拒绝服务 Denial of Service
- 引起拒绝行为的攻击。最常见的 DoS 攻击就有 计算机网络宽带攻击、连通性攻击。
DDoS:分布式拒绝服务 Distributed Denial of Service
- 处于不同位置的多个攻击者同时向目标发动攻击。
XSS:跨站脚本攻击(Cross-Site Scripting)
- 攻击者在 Web 页面中插入恶意 html 代码。当用户浏览网页的时候,嵌入其中 Web 里面的 html 代码会被执行,从而达到恶意攻击用户的特殊目的。
问题:XSS 攻击
Cross-Site Scripting(跨站脚本攻击)简称 XSS,是一种 代码注入攻击。攻击者通过在目标网站上注入恶意脚本,使之在用户的浏览器上运行。利用脚本,攻击者可获取用户 Cookie、SessionID 敏感信息,进而危害数据安全,或实施其他攻击。
- 攻击方式:
- 反射类:在 URL 中注入脚本,用户访问后会自动执行脚本。通常浏览器会自动拦截。
- 存储类:向服务器 post 恶意脚本,如留言板信息提交。通常前端/服务器进行过滤/转义可解决。
- 可继续实施的其他攻击:恶意后台注入到服务器中,获取服务器的数据。CSRF 攻击。删除/篡改服务器关键数据。DDos 攻击等。
防御方法
要对用户提交的 URL 参数、Post 参数、Ajax 请求等进行过滤:对用户输入过滤、对输出进行编码。
-
httpOnly:在 cookie 中设置 HttpOnly 属性后�,js 脚本无法读取 cookie 信息,只能由服务器设置。
-
输入处理:过滤。对用户的输入内容 和格式检查,例如:邮箱,电话号码,用户名,密码。防止恶意代码注入数据库。
- 黑名单过滤:对危险的文本
<script>等参数进行拦截和过滤。 - 白名单过滤:白名单来控制允许的标签和标签属性。只有白名单中出现的才符合标准,其他转译。
- 白 / 黑名单配合。白名单过滤富文本,转义所有字符成本太高,白名单通常过滤用户名、密码等
- 黑名单过滤:对危险的文本
-
输出处理:转义 HTML:如果需要拼接 HTML 等代码,需要对于引号,尖括号,斜杠进行转义。
问题:CSRF 攻击
跨站请求伪造(英语:Cross-site request forgery)缩写为 CSRF 或者 XSRF。
一个 CSRF 攻击需要 2 个条件:
- 用户登录了一个受信任的网站 A,并且本地存放了登录 Cookie;
- 在不关闭 A 的情况下,访问了危险网站 B(如打开图片、打开链接等);
- 只要 A 网站没有做好相应的 CSRF 防护,用户就会中招,攻击者并不需要获取受害者的 Cookie。
- 比如,用户点击了恶意图片 img,而 img 的 src 访问了网站 A 的转账接口。由于当前用户没有退出登录,所以会在用户不知情下转账成功。
防御方法
-
验证码,用户发送请求前,需要填写验证码,确保是用户自行发出的请求。
- 缺点:不能每个请求都添加验证码,影响用户体验。
-
同源检测,HTTP 请求有两个 Header 字段(Origin、Referer),用于标记来源域名。
- 在浏览器发起请求时会自动携带,且不能修改。 服务器通过 Referer 确定来源是否和 Origin 相同。
- 缺点:官方浏览器遵循了 HTTP 标准,不能修改 Referer。如果是恶意浏览器,可以修改。
-
Anti CSRF Token,保持登录的随机 token 不再放在 cookie 里,而是
- 方法一:在页面加载完成后,使用 JS 遍历整个 DOM 树,在 DOM 中所有地址是本站的链接标签中加入 token,让请求 URL 自带 token。
- 方法二:后端返回的 HTML 中,通过 body、html、header、meta 等标签中携带 CSRF-Token,客户端每次提交请求时,再把 token 携带并发送回去。
- 服务器收到请求,都会验证 token,如果一致则处理请求。同时,token 每验证一次,下次服务器就会发送一个新的 token。token 的变化具有不可预测性。
CSRF 与 XSS 区别
- 通常来说 CSRF 是由 XSS 实现的,CSRF 时常也被称为 XSRF(CSRF 实现的方式还可以是直接通过命令行发起请求等)。
- 本质上讲,XSS 是代码注入问题,CSRF 是 HTTP 问题。 XSS 是内容没有过滤导致浏览器将攻击者的输入当代码执行。CSRF 则是因为浏览器在发送 HTTP 请求时候自动带上 cookie,而一般网站的 session 都存在 cookie 里
问题:DNS 域名系统
功能:Internet 的命名系统。将用户认知的域名,解析为主机能识别的 IP 地址。
四种服务器:
-
本地域名服务器:本地个人/公司/大学。
- 主机发送 DNS 查询请求时,先发送给本地域名服务器。
-
根域名服务器:知道所有顶级域名服务器。
- 本地域名服务器无法解析,首先求助于根域名服务器。
-
顶级域名服务器:负责该服务器下所有的二级域名服务器。
-
权限域名服务器:一个区。
域名转换过程:递归 + 迭代(常用)、递归 + 递归。
- 某进程需要查询域名的 IP 时,基于 UDP 用户数据报发送查询信息。
- 先查看 主机 是否有缓存,再向本地域名服务器查询。
- 本地域名服务器 先查询本服务器是否有缓存,找不到则返回下一个查询地址(根)
- 根域名服务器 先查询是否有缓存,找不到则返回下一个查询地址(顶级)
- 顶级域名服务器 先查询是否有缓存,找不到则返回下一个查询地址(顶级 / 权限)
- 顶级域名服务器 先查询是否有缓存,找不到则返回下一个查询地址(权限)
关于缓存:
- 本地服务器,初次是没有缓存列表的。经过一次查询后,得到 IP 地址,会加入缓存中。
- 缓存的地址有生命周期,到期后自动删除。防止长期不访问 / 地址失效。
- 缓存的地址如果不可达,则证明虽然未到生命周期,但地址失效,则删除地址。
![截屏2022-08-12 10.32.23[40]](/assets/images/截屏2022-08-12 10.32.23-83e5562016ddba8f664fd5b03adb6cb9.png)