Chrome,存储,循环
Chrome 进程架构
Chrome 浏览器包括:1 个浏览器(Browser)主进程、1 个 GPU 进程、1 个网络(NetWork)进程、多个渲染进程和多个插件进程。
-
浏览器进程。主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
-
渲染进程。核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
- JavaScript 引擎线程:V8 引擎
- 定时触发器线程:setTimeout,setInterval。计数完毕后,将事件加入任务队列的尾部,等待 JS 引擎线程执行。
- 事件触发线程:回调。将准备好的事件交给 JS 引擎线程执行。
- 异步 http 请求线程:负责执行异步请求一类的函数的线程,如:Promise,axios,ajax 等。
-
GPU 进程。其实,Chrome 刚开始发布的时候是没有 GPU 进程的。而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
-
网络进程。主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
-
插件进程。主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
打开 1 个页面至少需要 4 个进程:
- 网络进程、浏览器进程、GPU 进��程、渲染进程(同一个站点,多个标签页共用一个渲染进程);
- 如果打开的页面有运行插件的话,还需要再加上 1 个插件进程。
渲染进程架构(5)
-
主线程:内有 JS 引擎线程,主要用于处理 js 代码(解析、执行)。只要消息队列不为空,就会一直从中取任务执行。由于主线程和 GUI 线程的互斥,所以当一个 js 任务执行过长时,会阻塞页面的渲染,造成页面的卡顿。
-
GUI 渲染线程:负责解析 HTML、CSS、合成 CSSOM 树、布局树、绘制、分层、栅格化、合成。重绘、重排、合成都在该线程中执行。
- GUI 线程和 JS 引擎线程是冲突的,当 GUI 线程执行时,js 引擎线程会被挂起;当 js 引擎线程执行任务时,有需要 GUI 线程执行的任务,会被保存到一个队列中,等待 js 引擎执行完执行。
-
事件触发线程:当 js 代码在解析时,遇到事件时,比如鼠标监听,会将这些任务添加到事件触发线程中。等事件触发时,会将任务从事件触发线程中取出,放到消息队列的队尾等待执行。
-
定时器触发线程:用于存放 setTimeout、setInterval 等任务,在解析遇到这些任务时,js 引擎会将这些任务放到定时器触发线程中,并开始计数,时间到了之后,将任务放到消息队列中等待执行。
-
http 请求线程:检测 XMLHttpRequest 请求,当请求状态改变时,将设置的回调函数添加到消息队列中等待执行。
浏览器工作流程
HTTP 请求流程
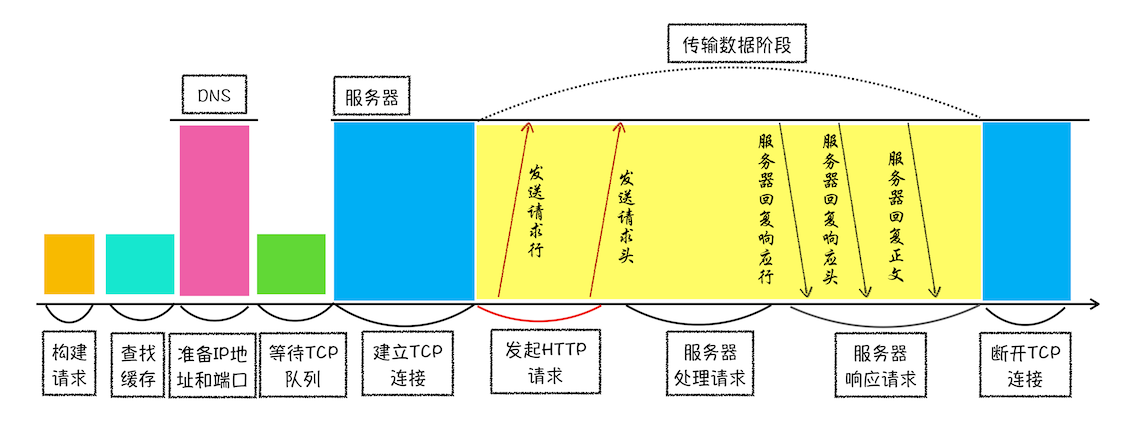
首先会划分为两个流程:
- 浏览器端(的网络线程)发起 HTTP 请求流程,包括 6 个阶段:
- 构建请求、查找缓存、准备 IP 和端口、等待 TCP 队列、建立 TCP 连接、发送 HTTP 请求。
- 服务器端处理 HTTP 请求流程,包括 3 个阶段:
- 处理请求、响应请求、断开 TCP 连接。
(1)浏览器端:
-
构建请求:浏览器构建 请求行 信息,为发起网络请求做数据准备。
-
查找缓存:在浏览器缓存中查询是否有要请求的文件。
- 在浏览器缓存中存有副本:那么它会拦截请求,返回该资源的副本,并直接结束后续请求。
- 没有发现副本:它会准备发起网络请求。
-
准备 IP 地址和端口:通过 URL 地址,来解析 IP 和端口信息。
- 浏览器会先查找自身的 DNS 数据缓存服务 ,如果域名之前解析过了,浏览器会直接得到 IP 和端口信息。
- 否则,会向 DNS 服务器申请查找 URL 地址的 IP 信息。
-
等待 TCP 队列
- 同一个域名同时最多只能建立 6 个 TCP 连接。如果当前队列已满,需要等待。
-
建立 TCP 连接:通过 3 次握手建立 TCP 连接;
-
发送 HTTP 请��求:浏览器会依次发送:请求行、请求头 和 请求体。
(2)服务器端
- 处理请求:服务器收到来自浏览器的请求后,会分析请求,然后给出相应;
- 响应请求:依次发送:响应行、响应头 和 响应体。
- 断开 TCP 连接:4 次挥手断开链接。
- 如果头信息中有:
Connection:Keep-Alive,则不会断开仍然保持打开状态。
- 如果头信息中有:
输入 URL 到页面展示
这里面涉及到四个进程的分工合作:
- 浏览器进程:负责用户交互、其他进程管理、文件存储等。
- 渲染进程:负责把从网络下载的 HTML、JavaScript、CSS、图片等资源解析为可以显示和交互的页面。
- 网络进程:为浏览器进程和渲染进程提供网络下载功能。
- GPU 进程:为渲染进程提供栅格化加速,加快生成位图。
完整的过程,分为两大阶段,导航 和 渲染:
🌈 第一阶段:导航阶段
用户发出
URL 请求到页面开始解析。
用户可以感知到的导航阶段,就是在浏览器的地址栏里面输入了一个地址后,之前的页面没有立马消失,而是要加载一会儿才会更新出空白页面。
此时的状态:
- 屏幕 正展示之前已经渲染好的页面。
- 浏览器进程 中存有这个页面的状态。
- 用户 输入在地址栏输入了一串关键字。
- 地址栏 分析用户输入的内容,然后生成对应的 URL 请求。
详细过程:
-
用户:输入内容
- 浏览器进程 接收到地址栏的 URL 请求,便将该 URL 转发给 网络进程。
-
网络进程:提交 URL 请求,
-
如果是 HTTP 协议,此时会发起一个 HTTP 请求,见相关问题:
-
构建请求、查找本地资源缓存、查找本地 DNS 缓存、DNS 获取 IP 和端口、
-
等待 TCP 队列、建立 TCP 连接、发送 HTTP 请求
-
-
网络进程 发起真正的 URL 请求。
-
服务器 收到 URL 请求,返回 响应头。
-
网络进程 收到 响应头数据,解析 响应头数据,然后 转发 给浏览器进程。
- 301 重定向
- 分析数据类型是获取其实资源,还是获取一个 HTML 页面。
- 断开 TCP 连接,或者
Connection:Keep-Alive保持连接。
-
-
浏览器进程:准备渲染进程
- 浏览器进程 收到 数据 ,发送 提交导航 (CommitNavigation)消息 到渲染进程。
- 渲染进程 收到消息后,直接和网络进程建立 数据管道,准备接收 HTML 数据。
-
渲染进程:提交文档
-
渲染进程 向浏览器进程 确认提交,告诉浏览器进程:“已经准备好接受和解析页面数据了”。
-
浏览器进程 收到 确认提交 后,便移除之前旧的文档,然后 更新 浏览器进程中的页面状态。
-
🌈 第二阶段:渲染阶段
渲染出显示的页面,然��后展示在屏幕上。
用户可以感知到的渲染阶段,就是空白页面要过一段时间,才会刷新为有内容的漂亮网页。
此时的状态:
-
浏览器进程 等待渲染进程提交新页面;
-
渲染进程 开始渲染网页。
-
网络进程 在渲染进程执行网页渲染时,同步下载 HTML、CSS、JavaScript 和图片等资源。
详细过程:
- DOM。 渲染进程 将 HTML 内容转换为能够读懂的 DOM 树 结构。
- CSSOM。 渲染引擎 将 CSS 样式表 转化为浏览器可以理解的 styleSheets,构建 CSSOM。并计算出 DOM 节点的样式。
- Layout。 渲染引擎 创建 布局树,并计算元素的布局信息。
- Layer。 渲染引擎 对布局树进行分层,并生成 分层树。
- Paint。 渲染引擎 为每个图层生成 绘制列表,并将其提交到 合成线程。
- 合成线程 进行栅格化 (raster) 操作:
- tiles。 先将图层分成 图块,
- raster。 然后在 光栅化线程池 中将图块转换成 位图,
- draw quad。 最后发送 绘制图块命令 DrawQuad 给浏览器进程。
- display。 浏览器进程 根据 DrawQuad 消息生成 页面,并 显示 到显示器上。
导航过程的页��面变化
🤔 从输入 URL 到网页最终展示的过程中,页面在视觉上会发生几次变化?
从发起 URL 请求开始,到首次显示页面的内容,在视觉上经历的三个阶段,按照时间顺序:
- 导航阶段开始(即将构建 URL 请求)。
阶段一:展示之前页面内容,没有更新。
- 导航阶段结束,渲染阶段开始(渲染进程开始从网络进程获取 HTML 文件)。
阶段二:展示空白页面,更新了:前进后退、安全状态、地址了 URL。
- 渲染阶段结束(页面被绘制出来)。
阶段三:展示渲染的页面内容。
性能影响:
阶段一:主要受是网络质量或者是服务器处理时间的影响
阶段二:见,“如何缩短白屏时间” 相关问题。
DOM 相关
从网络传给渲染引擎的 HTML 文件字节流是无法直接被渲染引擎理解的,所以要将其转化为渲染引擎能够理解的内部结构,这个结构就是 DOM。
在渲染引擎中,DOM 有三个层面的作用:
- 从页面的视角来看,DOM 是生成页面的基础数据结构。
- 从 JavaScript 脚本视角来看,DOM 提供给 JavaScript 脚本操作的接口。通过这套接口,JavaScript 可以对 DOM 结构进行访问,从而改变文档的结构、样式或内容。
- 从安全视角来看,DOM 是一道安全防护线,一些不安全的内容在 DOM 解析阶段就被拒之门外了。
DOM树生成,解析 HTML
两个重点:
-
HTML 解析器:在渲染引擎中(渲染进程),有一个叫 HTML 解析器(HTMLParser)的模块,它的职责就是负责将 HTML 字节流 转换为 DOM 结构。
-
边加载边解析:HTML 解析器并不是等整个文档加载完成之后再解析的,而是网络进程加载了多少数据,HTML 解析器便解析多少数据。
具体流程:
-
网络进程接收到响应头之后,会根据响应头中的
content-type字段来判断文件的类型:- 如果
content-type的值是text/html,就判断这是一个 HTML 文件,然后为该请求 选择/创建一个渲染进程。
- 如果
-
渲染进程准备好之后,网络进程和渲染进程之间会建立一个 共享数据的管道:
-
网络进程 通过 TCP 连接服务器,获取到按序到达的字节流,同时就传递到管道中;
-
渲染进程 则从管道中读取字节流,然后让 HTML 解析器动态地解析为 DOM 树。
-
Js 和 CSS 阻塞 DOM
JavaScript 和 CSS 文件的加载(下载),会阻塞 DOM 树的构建(Parse HTML)吗?
结论:CSS 文件不阻塞 DOM 的生成,不阻塞 Javascript 的加载,但是会阻塞 JavaScript 的执行。
JavaScript 文件阻塞 DOM 树构建:
如果在渲染进程中 HTML 解析器在逐行解析 HTML 文件时,当解析到 <script> 标签,渲染引擎会判断这是一段脚本,此时 HTML 解析器就会暂停 DOM 的解析,因为接下来的 JavaScript 可能要修改当前已经生成的 DOM 结构。这时候 HTML 解析器暂停工作,JavaScript 引擎介入,并执行 script 标签中的这段脚本。当这段脚本执行完毕后,HTML 解析器才会继续解析 DOM。
- Chrome 浏览器对此做了一个优化,预解析操作。当渲染引擎收到字节流之后,会开启一个 预解析线程,用来分析 HTML 文件中包含的 JavaScript、CSS 等相关文件,解析到相关文件之前,预解析线程会提前下载这些文件。当然,如果解析到了 JavaScript 文件的位置,JavaScript 文件还没有下载完,依然会发生阻塞问题。
情况一:在执行 Parse HTML 的时候,如果遇到 内联的 JavaScript 脚本,那么会暂停当前的 HTML 解析而去执行 JavaScript 脚本,在 JavaScript 脚本执行完毕后,再继续往下解析
情况二:如果内联的脚本替换成 js 外部文件。这种情况下,当解析到 JavaScript 的时候,会先暂停 DOM 解析,并下载 foo.js 文件。等待下载完成后,执行这段 JS 文件,然后再继续往下解析 DOM。
CSS 间接阻塞 DOM 树构建:
如果代码里 先 引用了外部的 CSS 文件,那么在执行 后面的 JavaScript 之前,要等待这个 CSS 文件下载完成,并解析生成 CSSOM 对象之后,才能执行 JavaScript 脚本。
- 因为 JavaScript 代码有可能会访问元素样式,而按照文档从上至下的顺序,在上面的 CSS 文件有可能修改了这些元素的样式。
- JavaScript 引擎在解析 JavaScript 之前,是不知道 JavaScript 是否操纵了 CSSOM 的,所以渲染引擎在遇到 JavaScript 脚本时,不管该脚本是否操纵了 CSSOM,都会执行 CSS 文件下载,解析操作,再执行 JavaScript 脚本。
使用 async 和 defer 标签,会有不同的表现效果:
| script 标签 | 多个 JS 文件的执行顺序 | 是否阻塞解析 HTML |
|---|---|---|
<script> | 顺序执行(HTML 中的引入顺序) | 阻塞 |
<script async> | 乱序执行(下载完成的顺序) | 可能阻塞,也可能不阻塞 |
<script defer> | 顺序执行(HTML 中的引入顺序) | 不阻塞 |
script
浏览器在解析 HTML 的时候,如果遇到一个没有任何属性的 script 标签,就会 暂停解析 HTML。先发送网络请求下载 JS 文件,然后执行该代码。当代码执行完毕后继续解析。
- 为什么暂停解析 HTML?
- 因为如果解析到
<script>标签时,渲染引擎判断这是一段脚本,此时 HTML 解析器就会暂停 DOM 的解析,因为接下来的 JavaScript 可能要修改当前已经生成的 DOM 结构。
async script
当浏览器遇到带有 async 属性的 script 时,异步 下载该脚本**,不阻塞浏览器解析 HTML**,一旦下载好 Js 文件,
- 如果此时 HTML 解析尚未完成,就会 暂停解析 HTML,先执行 JS 代码,后继续解析。
- 如果此时 HTML 解析早已完成,则 没有产生阻塞,按下载完成的顺序去执行 JS 文件。
defer script
当浏览器遇到带有 defer 属性的 script 时,异步 下载该脚本,不阻塞浏览器解析 HTML。等待 HTML 解析完毕后,再执行 JS 代码。
优化:CSS 和 Js 加载
如何优化 CSS 和 JavaScript 阻塞 DOM 树的构建(Parse HTML)?
- 官方优化:Chrome 浏览器对此做了一个优化,预解析操作。当渲染引擎收到字节流之后,会开启一个 预解析线程,用来分析 HTML 文件中包含的 JavaScript、CSS 等相关文件,解析到相关文件之前,预解析线程会提前下载这些文件。
- 自己优化:
- CDN 来加速 JavaScript 文件的加载;
- 压缩 JavaScript 文件的体积;
- 如果 JavaScript 文件中没有操作 DOM 相关代码,就可以将该 JavaScript 脚本设置为 异步加载,通过
async或defer。async标志的脚本文件一旦加载完成,会立即执行;defer标记的脚本文件,在DOMContentLoaded事件之前执行。DOMContentLoaded: 当页面的内容解析完成后,则触发该事件。onLoad: 等待页面的所有资源都加载完成才会触发,这些资源包括 css、js、图片视频等。
Js 存储
JavaScript 是动态语言,在声明变量之前不需要确认变量的数据类型。JavaScript 引擎在运行代码的时候自己会计算出变量的类型。
JavaScript 是弱类型语言,它支持隐式类型转换。可以使用同一个变量保存不同类型的数据。
- JavaScript 有 7 种原始类型数据:null、undefined、number、boolean、string、symbol、bigInt
- JavaScript 有 1 种引用类型数据:object
JavaScript 在执行过程中, 有三种类型内存空间:
-
代码空间:存储可执行代码。
-
栈空间:运行时调用栈,存储执行上下文、原始类型数据。
-
堆空间:存储闭包、引用类型数据;
- 对象类型:存放在堆空间,栈空间中只是保留了对象的引用地址。当 JavaScript 需要访问该数据的时候,是通过栈中的引用地址来访问的。
问题:为什么要把引用数据类型存在堆内存中
- 因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。
所以通常情况下,栈空间的体积偏小,主要用来存放原始类型的小体积数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到空间更大的堆中。堆内存的缺点是 分配内存 和 回收内存 都会有一定的开销。
闭包的存储机制
闭包存储在堆空间中。产生闭包的核心有两步:
-
第一步是需要预扫描内部函数;
-
第二步是把内部函数引用的外部变量保存到堆中。
当 JavaScript 引擎执行到一个函数(foo)时:
-
首先进入��编译阶段,创建一个空执行上下文,然后依次声明函数内部变量,做变量提升;
-
之后进入运行阶段,当这个函数内的内部函数,引用了函数内的外部变量,这就形成了一个 闭包。
- 所以,此时会在堆内存中创建一个
closure(foo)对象,存储内部函数所引用的变量; - 然后,在
foo执行上下文中的环境变量中,不在存储这些变量的信息,通过引用closure(foo)对象获取;
- 所以,此时会在堆内存中创建一个
-
最后当
foo函数执行完毕,返回这个内部函数(对象)后,foo执行上下文销毁,内部函数没有引用的变量也销毁;-
在堆内存中的
closure(foo)依然保存了变量引用; -
返回的函数(对象)中,内部属性
[[Scopes]]保存了对Closure(foo)的引用,可以顺利访问到闭包的内容。
-
内存泄露
如果有大量的变量在业务上已没有实际意义,但却因被引用而无法正确被 GC 回收,最终导致占用内存,这个现象就叫内存泄露。
内存泄露的情况:
- 全局变量。全局变量会一直被引用,无法被 GC 回收。
- 闭包。闭包如果被引用,就无法被 GC 回收。
- 被遗忘的定时器。
setInterval会周期性的调用回掉函数,有时会忘记对setInterval进行删除。 - DOM 引用。考虑到性能或代码简洁方面,我们代码中进行 DOM 时会使用变量缓存 DOM 节点的引用,但移除节点的时候,我们应该同步释放缓存的引用,否则游离的子树无法释放。
Js 垃圾回收
垃圾回收的处理方式:
-
手动回收:C/C++ 使用手动回收策略,何时分配内存、何时销毁内存都是由代码手动控制的。
-
自动回收:JavaScript、Java、Python 等语言,产生的垃圾数据是由垃圾回收器来释放的。
数据是存储在栈和堆两种内存空间中的,分别介绍 栈中的垃圾数据 和 堆中的垃圾数据 是如何回收的:
- 🍊 栈中的垃圾数据:通过 ESP 指针的移动,直接抛弃。
- 🍊 堆中的垃圾数据:垃圾回收器 通过三个步骤:标记对象、回收内存、整理内存,完成回收工作。
栈的垃圾回收
调用栈是 JS 引擎用来追踪函数调用执行过程的数据结构,遵循后进先出原则。
- 满足栈的性质:入栈、出栈、栈顶指针。而实际上是编译器优化下的 “栈帧链表 + 栈区模拟结构”。
-
入栈:当遇到一个新的函数调用时,会新建这个函数执行上下文,然后入栈,向上移动 ESP 指针到这个新的函数上下文上。
-
出栈:当这个函数执行结束之后,Js 引擎会向下移动 ESP 来取消栈中对这个上下文的引用;
- 这个执行上下文,其依然保存在栈内存中,但已经是无效内存了。
-
入栈:有新的��函数需要调用时,这块内容会就会被直接覆盖掉,实现了栈内存中的数据回收。
堆的垃圾回收
堆中的垃圾数据,用到 Js 中的 垃圾回收器。
(1)代际假说
是一个垃圾回收的基础理论:大部分对象在内存中存在的时间很短。
- 很多对象一经分配内存,很快就变得不可访问(不再使用,没有指针指向这些对象);
(2)分代收集
分代收集是 V8 引擎采用的垃圾回收策略。
在 V8 中会把堆分为 新生代 和 老生代 两个区域。
- 新生代:存放生存 时间短的对象,新生区通常只支持 1~8M 的容量,副垃圾回收器 控制;
- 老生代:存放生存 时间久、结构复杂的对象。老生区支持非常大的容量。主垃圾回收器 控制
(3)垃圾回收器的工作流程
不论什么类型(主/副)的垃圾回收器,它们都有一套共同的执行流程。
-
第一步:标记对象。标记空间中 活动对象(还在使用的对象) 和 非活动对象(可以进行垃圾回收的对象)。
-
第二步:回收内存。回收非活动对象所占据的 内存,统一清理内存中所有被标记为可回收的对象。
-
第三步:整理内存。频繁回收对象后,内存中就会存在大量不连续空间,称为内存碎片。需要移动内存碎片,空出连续的空间,
- 当内存中出现了大量的内存碎片,如果需要分配较大连续内存的时候,就有可能出现内存不足的情况。
副垃圾回收器
- 副垃圾回收器主要负责新生代,垃圾回收比较频繁。
Scavenge 算法 :把新生代空间对半划分为:对象区域 + 空闲区域。新加入的会到对象区,当其快被写满时,会执行一次垃圾清理操作,流程如下:
- 标记可达对象:遍历调用栈中的全部变量,以每一个变量为根元素,遍历这组根元素。所有遍历过程中,能到达的元素称为 活动对象,没有到达的元素判断为 垃圾数据。
- 回收内存:将可达的对象全部复制到空闲区。
- 整理内存:复制过程中,把对象进行有序排列,完成碎片整理。
- 角色反转。原来的对象区变成空闲区,实现反转;
- 对象晋升。经过 两次 垃圾回收依然还存活的对象,会被移动到老生区中。
主垃圾回收器
老生区中的垃圾回收。对象来源:(1)大体积对象会直接被分配到(2)从新生区晋升而来的对象(存活时间长)。
流程如下:
- 标记可达对象:和刚才遍历方式相同,对可达对象标记,
- 回收内存:标记 - 清除(Mark-Sweep),直接清理掉不可达的垃圾对象。
- 整理内存:标记 - 整理(Mark-Compact),几次清除后,把剩余对象向一端移动(整理内存),避免碎片。
V8 引擎优化
问题:全停顿(Stop-The-World):
- 由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。这种行为叫全停顿。
解决:增量标记(Incremental Marking):
- 这其中,对象标记需要遍历整个调用栈和堆内存中的所有对象,非常耗时。
- 增量标记算法,可以把一个完整的垃圾回收任务拆分为很多小的任务。执行时间缩短,穿插在其他 Js 任务中间执行;
页面循环系统
消息队列 / 任务循环
浏览器页面是由消息队列和事件循环系统来驱动的。
- 每个渲染进程都有一个主线程,要处理 DOM、计算样式、处理布局、 JavaScript 任务以及各种输入事件。
- 要让这么多不同类型的任务在主线程中有条不紊地执行,这就需要一个系统来统筹调度这些任务,这个统筹调度系统就是 消息队列和事件循环系统。
🍊 事件循环机制
可以想象成线程是一个 for 循环语句,会一直循环执行。在线程运行过程中,一直等待事件触发,比如在等待用户输入的数字,一旦接收到用户输入信息,那么线程就会背激活,然后执行相加运算,最后输出结果。
🍊 消息队列
消息队列 是一个队列数据结构,存放了主线程要执行的任务。符合队列的先进先出特点。
- 渲染进程专门有一个 IO 线程 用来接收其他进程传进来的消息,接收到消息之后,会将这些消息组装成任务发送给渲染主线程。
- IO线程 往队列尾部添加任务,等待执行;主线程 从队列头部取出任务,并执行。
🍊 进程间通信
不同进程之间无法直接共享内存,需要借助操作系统提供的跨进程通信 IPC(Inter-Process Communication)
- 利用 IPC,IO线程接收到来自网络进程发来的资源加载完成信息、来自浏览器进程发来的用户鼠标点击信息,然后添加到消息队列中,等待主线程将它们处理。
- 常见方式 1:共享内存。多个进程共享一块无力内存区域 + 信号量同步机制;
- 常见方式 2:消息队列。操作系统内核维护一个消息缓冲区;
🍊 浏览器事件循环
(1)浏览器的结构:1 个浏览器(Browser)主进程、1 个 GPU 进程、1 个网络(NetWork)进程、多个渲染进程和多个插件进程。
-
浏览器进程。主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
-
渲染进程。核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全�考虑,渲染进程都是运行在沙箱模式下。
- 主线程:处理 js 代码(解析、执行)。只要消息队列不为空,就会一直从中取任务执行。由于主线程和 GUI 线程的互斥,所以当一个 js 任务执行过长时,会阻塞页面的渲染,造成页面的卡顿。
- GUI 渲染线程:负责解析 HTML、CSS、合成 CSSOM 树、布局树、绘制、分层、栅格化、合成。重绘、重排、合成都在该线程中执行。
- GUI 线程和 JS 引擎线程是冲突的,当 GUI 线程执行时,js 引擎线程会被挂起;当 js 引擎线程执行任务时,有需要 GUI 线程执行的任务,会被保存到一个队列中,等待 js 引擎执行完执行。
- 事件触发线程:当 js 代码在解析时,遇到事件时,比如鼠标监听,会将这些任务添加到事件触发线程中。等事件触发时,会将任务从事件触发线程中取出,放到消息队列的队尾等待执行。
- 定时器触发线程:用于存放 setTimeout、setInterval 等任务,在解析遇到这些任务时,js 引擎会将这些任务放到定时器触发线程中,并开始计数,时间到了之后,将任务放到消息队列中等待执行。
- http 请求线程:用于检测 XMLHttpRequest 请求,当请求状态改变时,将设置的回调函数添加到消息队列中等待执行。
-
GPU 进程。其实,Chrome 刚开始发布的时候是没有 GPU 进程的。而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
-
网络进程。主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
-
插件进程。主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
(2)事件循环的结构
浏览器页面是由「消息队列」和「事件循环系统」来驱动的。他们统筹调度上述线程产生的任务,让各种类型的任务在主线程中有条不紊地执行。
- 系统调用栈:和 Js 执行时一样,浏览器在运行时也有一个系统调用栈,在开发工具中可以看到 “火焰图”;
- 宏任务队列:俗称消息队列,先进先出,主线程从消息队列中顺次取出并执行宏任务;
- 微任务队列:每次宏任务执行完后清空;
- 延迟任务池:调度机制,setTimeout 等会注册在 timer 任务池中。倒计时完成后,回调回被推进任务队列中。
- rAF 回调队列:存储 requestAnimationFrame 时机要执行的任务,新增的任务会在下一帧渲染前执行。
- IdleCallback 队列:存储 requestIdleCallback 时机要执行的任务;
- 渲染相关队列:执行布局 layout->绘制 paint 任务。
(3)流程:浏览器每一帧要完成的工作
像 while(true) 循环一样 event loop 不断执行下边的步骤:没看完
- 执行一个宏任务:主线程从宏任务队列中,队头取出 1 个宏任务开始执行(v8 引擎);过程中产生了微任务,放入微任务队列中;
- 清空微任务队列:当 1 个宏任务执行完,开始清空微任务队列。
- 执行 rAF 回调:在渲染前,清空 request Animation Frame 队列中的回调任务;
- 渲染工作:判断是否更新渲染。渲染流程:重新计算样式->布局->绘制->合成;
- 更新时机:在一帧以内的�多次 dom 变动,浏览器不会立即响应,而是会积攒变动以接近 60HZ 的频率更新视图。
- 空闲时间:如果本轮时间空闲(16.67ms),取出 request Idle Callback 中一个任务执行;执行完若空闲,继续取出执行;
- 延迟任务判断:下一轮循环任务准备阶段,检查计时器池、网络响应池等延迟任务中,到期任务的回调加入宏任务队列中;
补充:宏任务和微任务 🔗
在渲染进程中,把消息队列中的任务称为 宏任务,每个宏任务中都包含了一个 微任务队列。
宏任务和微任务的加入,使任务执行实现了 效率 和 实时性 的平衡。
- 效率:宏任务按序执行,没有饿死;
- 实时性:微任务优先级更高,不需要消息队列等待,优先执行完毕。
定义:
- 宏任务:setTimeout、setInterval、XMLHttpRequest (I/O 线程)、UI 渲染等。
- 微任务:Promise.then (回调)、MutationObserver (监控 DOM 节点) 等。
🍊 Node 事件循环
相比浏览器事件循环的主要区别:
- 主线程:浏览器是渲染线程 + JS 引擎;Node 是 JS 执行线程;
- 执行节奏:浏览器有 60fps 的约束,Node 没有帧率限制,也没有 rAF、idle 的回调;
- 事件循环:浏览器是宏任务 + 微任务 + 渲染帧;Node 是 6 个阶段任务轮询 + 微任务;
- 微任务:浏览器只有一个微任务队列,Node 有 nextTick 和 Promise 两个。
nodeJs 中,使用 libuv 引擎(事件驱动的异步 I/O 库)实现事件循环。
libuv 引擎中事件循环分为 6 个阶段顺次执行。当执行到某个阶段时,有两个情况会跳转到下一个阶段:
- 当前队列执行为空、执行当前队列的任务数量 / 时间达到阈值。
六个阶段:
Node.js 是事件驱动的,会始终在运行中,如果没有任务,则一直在 poll 阶段等待:
- 有 I/O 事件就去执行回调;没有的话就阻塞等待,直到有事件到来或超时;如果有定时器快要到期,也会提前结束阻塞进入下一阶段。
-
timers 阶段:执行定时器到期回调 setTimeout、setInterval。
-
pending callbacks 阶段:执行上一轮循环中未执行的系统操作,如 TCP 错误捕获、I/O 操作失败等。
-
idle,prepare 阶段:仅 node 内部使用,不开发给开发者
-
poll 阶段:获取新的 I/O 事件,执行 I/O 相关回调。
-
执行 poll 队列里的事件:除 timers/check/微任务,其他事件(文件系统、网络等异步操作)都在这里执行。
-
阻塞。进入 poll 时,即使没有要执行的事件,poll 也会一直等下去。
- 停止阻塞:其他队列中有可执行事件、达到阻塞最大时间。
-
-
check 阶段:执行
setImmediate()回调 -
close callbacks 阶段:执行关闭回调,例如:
socket.on('close', ...)
开发者常用:timers、poll、check 这三个阶段。
(2)微任务
和浏览器一样,每个宏任务中都附带一个微任务队列,所以微任务不受事件循环限制,只要微任务队列中有任务存在,就会优先执行。
- process.nextTick() 优先级高于 promise
- Promise.then()
宏任务 / 微任务
如果一次JS任务执行花费的时间过长,浏览器将无法执行其他任务,例如处理用户事件、页面渲染。
- 宏任务和微任务的加入,使任务执行实现了 效率 和 实时性 的平衡。
在渲染进程中,把消息队列中的任务称为 宏任务,每个宏任务中都包含了一个 微任务队列。
🍊 (1)宏任务
渲染进程内部会维护多个消息队列,在 Chrome 中主要有两个:延迟执行队列 和 消息队列。
宏任务主要包括了:
- 渲染事件(如解析 DOM、计算布局、绘制);
- 用户交互事件(如鼠标点击、滚动页面、放大缩小等);
- JavaScript 脚本执行事件;
- 网络请求完成、文件读写完成事件。
典型的触发宏任务的两种 WebAPI:
setTimeout:在进程内,将延迟触发的回调函数放入延迟队列中,在每个宏任务执行完毕后遍历延迟队列,寻找到期的任务,并执行。XMLHttpRequest:渲染进程的 IO 线程,通过 IPC 和网络进程沟通,通知网络进程去服务器请求资源。当返回资源后,渲染进程的 IO 线程把返回情况(成功?失败?故障?)封装为一个任务放在任务队列末尾。
🍊 (2)微任务
微任务就是一个需要异步执行的函数,执行时机是在主函数执行结束之后、当前宏任务结束之前。
当 JavaScript 执行一段脚本的时候,V8 会为其创建一个全局执行上下文,在创建全局执行上下文的同时,V8 引擎也会在内部创建一个 微任务队列。
**在当前宏任务执行的过程中,有时候会产生多个微任务,按序保存在微任务队列中。**所以异步使用微任务的一个优势是,同一次事件循环中,这些微任务的上下文环境是一致的。
微任务的产生有两种:
- 使用
MutationObserver监控某个 DOM 节点。目的是为了根据节点变化,通过 JavaScript 来修改节点、添加或删除部分子节点。当 DOM 节点发生变化时,就会产生 DOM 变化记录的微任务。 - 使用
Promise。当调用Promise.resolve()或者Promise.reject()的时候,产生微任务。
🍊(3)总结
-
微任务和宏任务是绑定的,每个宏任务在执行时,会创建自己的微任务队列。
-
微任务的执行时长会影响到当前宏任务的时长。
-
在一个宏任务中,分别创建一个用于回调的宏任务和微任务,无论什么情况下,微任务都早于宏任务执行。
为什么有宏/微任务
宏任务:解决单个任务执行时间过长
所有的任务都是在 单线程 中执行的,所以每次只能执行一个任务,而其他任务就都处于等待状态。如果其中一个任务执行时间过久,那么下一个任务就要等待很长时间。
- 如果在执行动画过程中,其中有个 JavaScript 任务因执行时间过久,占用了动画单帧的时�间,这样会给用户制造了卡顿的感觉。针对这种情况,JavaScript 可以通过 回调 功能来规避这种问题,也就是让要执行的 JavaScript 任务滞后执行。通过回调,
微任务:解决高优先级的任务
在执行宏任务的过程中,如果有高优先级的异步任务需要先处理,则就把这个任务添加到当前宏任务的微任务队列中,这样既不会影响到对宏人物的继续执行(效率),有保证了高优先级任务先被执行(实施性)。
- 一个典型的场景是监控 DOM 节点的变化情况(节点的插入、修改、删除等动态变化),然后根据这些变化来处理相应的业务逻辑。一个通用的设计的是,利用 JavaScript 设计一套监听接口,当变化发生时,渲染引擎同步调用这些接口,这是一个典型的观察者模式。
setTimeOut 如何实现的
消息队列中的任务是按序执行的。
setTimeout并不是在指定时间后立即执行,而是渲染进程会将回调任务添加到浏览器内的延迟队列(Timer queue)中。- 队列中维护定时器:开始时间、延迟时间、回调函数。
当事件循环执行完当前的宏任务队列后,会检查延迟队列中是否有任务已经达到设定的时间点。如果有,就将这些任务依次压入宏任务队列中,等待下一轮事件循环处理。
因此,setTimeout 的最小精度不能保证是精准的时间触发,它实际上受到以下两方面影响:
- 延迟时间是否已到达;
- 当前主线程��是否空闲;
即便定时器到期,也必须等待主线程空闲,才能调度执行。
在 Chrome 中,延迟队列通常是通过链表实现,会按时间优先级去管理。这个设计也服务于性能优化和任务调度的灵活性。